Intel's Larrabee Architecture Disclosure: A Calculated First Move
by Anand Lal Shimpi & Derek Wilson on August 4, 2008 12:00 AM EST- Posted in
- GPUs
Thread and Data Management: It's Time to Blow Your Mind
With both the recent NIVIDA and AMD graphics hardware launches, we spent quite a bit of time talking about thread management. Since Larrabee is designed to be more of a collection of general purpose scalar and vector processing units, and vertex, primitive and pixel data (along with associate shader programs) are software managed. As we discussed what a context is for AMD and NVIDIA graphics hardware, a true context is going to be a different thing altogether on Larrabee.
We do have to make a point of saying before proceeding that NVIDIA and AMD are under no obligation to actually tell us how their architecture is physically implemented. It is entirely possible that much of the attributes of the hardware are not actually attributes of the hardware but simply reflections of how hardware resources are used. In recent discussions with both companies about certain realities of their hardware revealed to us that the belief is if the system behaves like a specific physical implementation then it effectively is the same as that physical implementation.
Of course, we disagree. And it is possible that some of this has more similarity with NVIDIA and AMD than they are letting on. But we'll go on what we've got for now, and assume that what Intel is doing is as divergent as it sounds.
Each Larrabee core on a chip (of which it seems likely there will be some multiple of 8 in the final product) can maintain 4 simultaneous software threads (4 contexts are kept active at a time). This gives the appearance of 4 virtual physical processors to software running directly on the hardware even though all four threads are sharing a single resource. It is very likely that the major purpose of this is to hide some of the long latency we hit when going to memory for texture data and the like.
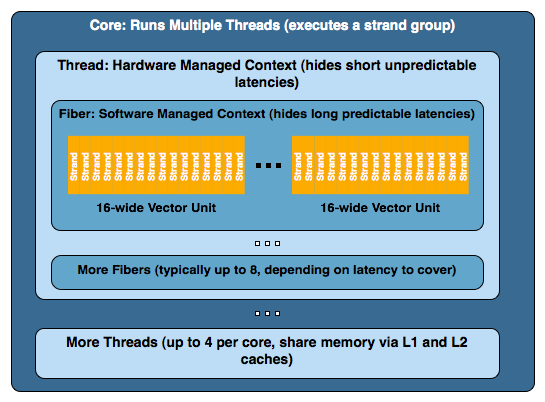
Now, for the purpose of graphics rendering using Intel's software rendering library or as it emulates DirectX and OpenGL, a thread is set up to manage the resources for a larger group of instructions and data that Intel calls a "fiber". Normally a thread will manage 8 fibers at a time. The hardware thread maintains a context in software for the fiber. The fiber's job is to manage the execution data parallel kernels on multiple groups of 16 "strands" (because the vector processor is 16-wide). A strand is what we have traditionally called a thread on other graphics hardware. The problem here is that Intel hardware is actually executing threads in a way that emulates hardware features of other architectures.
To put it together a little better, imagine one of Intel's threads as one of NVIDIA's TPCs, a fiber as an SM, and a strand as a thread. Okay, so it isn't that simple (simple?). But it is a sort of rough way of looking at it and a quick way of understand why naming is different here.
Let's take a deeper look at what goes on. With 4 threads per core (with at least 8 and hopefully something more like 32 cores), 8 fibers per thread, and some multiple of 16 strands per fiber, we could end up with a huge number of strands being managed simultaneously. This is active, running threads we are looking at as well. Since Larrabee will be a CPU in a true sense of the term, we can have as many threads as necessary live and waiting for a time slice. In the context of a normal CPU, this would be managed by the operating system, but as Larrabee will see the light of day as a graphics card, the driver will probably be managing timesharing issues an OS would normally perform.
While running ridiculous numbers of threads per core at a time might kill performance, unlike current GPUs, resource availability doesn't disrupt the creation of threads. Six of one, half dozen of the other? Maybe, and maybe not. Having active threads with data available to context switch to is key to hiding latency in NVIDIA and AMD hardware. If enough threads cannot be actively maintained, stalls happen and kill performance. Similar issues will impact Intel, and keeping dual-issue in-order hardware busy with multiple threads might be more easily managed if it can fall back on traditional CPU thread management paradigms to handle an abundance of threads that manage software that manages data parallel kernels.








101 Comments
View All Comments
erikespo - Monday, August 4, 2008 - link
http://en.wikipedia.org/wiki/Square_%28geometry%29">http://en.wikipedia.org/wiki/Square_%28geometry%29helpful page to take you back to first grade
and excuse my decimal point.. it is 204.49mm total per core or 14.3mm^2
erikespo - Monday, August 4, 2008 - link
Explain.lets use smaller numbers for you 2mm^2 is 2mm by 2 mm or 4 total mm
double that and it is 4mm^2 or 4 mm by 4 mm or 16mm total..
we are talking about area or 2 dimensions not 1 dimension.
Same math applies to the article
MamiyaOtaru - Monday, August 4, 2008 - link
No, you're way off. 2mm² is TWO square millimeters. (a rectangle 1x2 for example). Double that would be 4mm², which could either be 1x4 or 2x2.NUMBERmm² doesn't mean NUMBERxNUMBER mm, it means exactly what it says: NUMBER mm².
Using your smaller numbers: 2mm² is not "4 total mm"; it is TWO mm². Saying it is 4 total mm doesn't even make sense. You _can't_ measure area in millimeters. You measure it in square millimeters, and there are two of them (_2_mm²).
Here's an mspaint visual (if links work: http://img105.imageshack.us/my.php?image=squaremma...">http://img105.imageshack.us/my.php?image=squaremma...
You're so sure you're right on this, it's really depressing :(
darkequitus - Monday, August 4, 2008 - link
I did not appriciate the writer creaming over every digital page they wrote. especially when Larrabee's performance is mainl at the moment based on INtel hype and nothing real.ZootyGray - Monday, August 4, 2008 - link
THANK YOU.Somebody finally said it.
The others prefer Eutopian illusion - aka the curse aka ntel antitrust. ntel has no grafx and the fools in the public buy "inside' and nvid and ati aren't exactly friends of the curse.
welcome to the matrix. wakey wakey
ZootyGray - Monday, August 4, 2008 - link
and a 16 pager on maybe might could be should be = wannabe "employ-boy"- payday ? hooyeh. This is so disappointing for me. Credibility sags to a new low.
strikeback03 - Tuesday, August 5, 2008 - link
Someone whose two posts contain about 10 complete words and no complete thoughts says Anandtech's credibility has sagged to a new low?ZootyGray - Tuesday, August 5, 2008 - link
haha yeh - lots of room for thinking.or - if no thinkeez - ya gots der 16 pg inundation (that's a big word like marmalade) all based on nothing-is-real - you like that kind of brainwash? we don't know anything; but here's the tekspex?
btw - did u get it? the matrix idea? watch the movie. cos here it is. pardon my loaded cryptic literacy.
thx
if you don't get it - well, that's what they want - a world of sleeping mob. never mind, that's just my concern.
The Preacher - Monday, August 4, 2008 - link
I don't really care about how good it will be executing some software renderer but I feel it is going to kick ass in scientific calculations. Matrix operations, FFT/convolution, tremendous bandwidth, double precission... I may write C++/x86 assembly code directly for it and I may put this into a rack of servers and use it through MPI. Give me a compiler with vector intrinsic functions for it and my dreams just came true! :)elerick - Monday, August 4, 2008 - link
I have been a daily reader of another hardware review site for years. I ready nearly every articles that headlines and find many of them quite lacking. Today I got wind of your review for the Larabee. It was very well written and produced an amazing amount of tech knowledge not really commonly reviewed. I'm glad to have found you this site, and I never create an account but today I felt obligated to. Great work.PS: any news on that AMD / Fusion? or is that just them being intimidated by Intel's Larrabee?