NVIDIA's 1.4 Billion Transistor GPU: GT200 Arrives as the GeForce GTX 280 & 260
by Anand Lal Shimpi & Derek Wilson on June 16, 2008 9:00 AM EST- Posted in
- GPUs
Derek Gets Technical: 15th Century Loom Technology Makes a Comeback
Because it's multithreaded...
Yes I know it's horrible, but NVIDIA has gone a bit deeper in explaining their architecture to us and they thought borrowing terminology from weaving was clever. But as much as that might make you want to roll your eyes, the explanation of how things work that is enabled is worth it.
In cloth weaving, a warp is the vertical group of parallel threads that are held taught while the weft are the threads passed through these. I suppose it makes sense, then, that NVIDIA decided to call their grouping of parallel threads to be executed on an SM a warp.

See the group of threads that hang from the top of this loom? That's called a warp.
With each SM having 8 SPs and G80 having two SMs per TPC (for a total of 16 SPs) it looked like a natural fit to execute quads across these 16 scalar units. We learned that this was not the case, but seeing the grouping of three SMs per TPC in GT200 still looked a little funny until we really learned more about how things are scheduled on NVIDIA's unified architecture. Each SM's scheduler picks a new warp to work on every clock cycle, and since the scheduler runs at half speed this ends up being every other clock cycle from the perspective of the rest of the SM. Each warp is made up of a group of 32 threads (in pixel shaders this is a group of 8 quads) that share an instruction stream (a shader program or a kernel if you're talking about GPU computing).
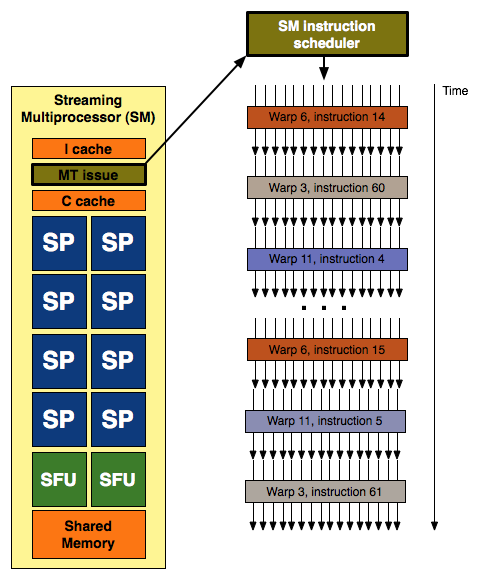
32 threads in a warp, issued in two groups of 16 threads - one such group is depicted above
Different warps built from threads executing the same shader program can follow completely independant paths down the code, but every thread within a warp must be exectuing the same instruction. This means that our branch granularity is 32 threads: every block of 32 threads (every warp) can branch independantly of all others, but if one or more threads within a warp branch in a different direction than the rest then every single thread in that warp must execute both code paths. Each threads only retains the result from the path it was supposed to follow probably by using the branch result to dynamically predicate the apporpriate path per thread. Each SM can have 32 (up from 24 in G80) warps in flight at the same time (for a total of 1024 threads in flight per SM). With 10 TPCs each containing 3 SMs, that's up to 30720 threads in flight on a GTX 280.
Each SM with it's 8 SPs and 2 SFUs is capable of processing up to 8 ops per clock (MAD (a fused floating point multiply and add) being the most complex) in the SPs and 8 ops per clock on the SFUs (which are made up of 4 floating point MUL units and other logic). Warps are executed on SMs in 2 groups of 16 threads (probably four quads for pixels) over four clock cycles.
This is where it gets interesting.
The SPs and SFUs are scheduled on alternating clock cycles from the perspective of the SM scheduler. They execute independent warps. SPs are scheduled on one clock cycle and SFUs are scheduled the next. Each is able to complete the processing of an entire warp before the next time it is scheduled, which happens to be four clocks (relative to the SPs and SFUs) after they it was scheduled with the last warp.
But wait ... aren't SMs supposed to be able to support dual-issue MAD+MUL? Well, back when G80 launched, Beyond3d did an excellent job of exploring the reality of the situation. With the fact that the SFU handles the "dual-issued" MUL and shares its time with other responsibilities like transcendental calculation and attribute interpolation, the ability of the hardware to actually accelerate cases that could take advantage of dual-issue was significantly reduced. But this scheduling revelation makes it clear that the problem is much more complex.
In order for code that could benefit from dual-issue hardware to take advantage of G80 or GT200, a warp must be scheduled on an SP for the MAD and then it must be re-scheduled on the SFU before it hits the SPs again. If the SFU is too busy handling attribute interpolation or transcendental math, then our warp will be rescheduled on the SPs to calculate the MUL and we will have lost our potential dual-issue speed up.
NVIDIA tells us that they "had some scheduling/issue problems with getting the MUL in the SFU to work consistently per clock. We fixed that in GT200." This makes perfect sense in light of what we now know about scheduling on G80/GT200. What they needed to do to improve the ability of their hardware to speed up cases where a MAD+MUL dual issue would help was to make sure that these cases were properly prioritized to execute on the SFU. We don't see MAD+MUL in every line of code, so giving these cases higher priority on the SFU than its other duties should help to optimize the utilization of the hardware. They do have to be careful not to start just running random MULs on the SFU because those special functions do still need to get done, but pushing a select subset of MULs onto the SFU (where they directly follow MADs that have just been executed on SPs) should definitely help in certain cases.
Really the main focus for NVIDIA is proper utilization and prioritization. Everything for any given frame needs to get done at some point or other, so simulating "dual-issue" shouldn't take priority over other things that need to get done that might be more important to completing the next frame. But organizing how to handle it is a big deal. Real time compilers are a big part of that, but internal thread management and scheduling in an architechure this wide also cannot be ignored. NVIDIA says they can now get 93-94% efficiency from their "dual-issue" implementation in directed tests and that this is significantly higher than on G80. Real world results will be lower, but the thing to remember is that the goal is simply to make maximally efficient use of the hardware availalbe. Just because the SFU isn't assisting in a MAD+MUL every clock doesn't mean it isn't doing something important.
This whole situation leaves us with mixed feelings. The hardware itself is not capable of "dual-issue" as it is understood in an architectural sense. The obfuscation of graphics hardware technology in a competitive industry has been the norm for the past decade, and we can accept this. We would prefer to know what the hardware is actually doing, but we are more than happy to have an explanation of something as a hardware feature where the hardware merely simulates the effect a specific architectural design has. But in the case where the hardware doesn't perform in nearly the same way as it would if the feature had actually been implemented as a hardware feature, we just can't help but be a little disappointed.
And we are conflicted about this because NVIDIA's design is actually very elegant. Attribute interpolation will always need to be done, and having hardware set aside for complex math is also very useful. But rather than making a dedicated fixed function interpolator or doing taylor expansion of complex math on SPs, NVIDIA built hardware that could serve both purposes and that had time left over to help offload some well placed MULs within the instruction stream of running programs.
If NVIDIA had been as open about their architecture as Intel is about their CPU designs, we could not have helped but to be impressed by this. The "missing MUL" wouldn't have been seen as a problem with NVIDIA's dual-issue "hardware"; we would have been praising NVIDIA's ability to schedule and multitask the different units within their SMs in order to improve utilization.








108 Comments
View All Comments
strikeback03 - Tuesday, June 17, 2008 - link
So are you blaming nvidia for games that require powerful hardware, or just for enabling developers to write those games by making powerful hardware?InquiryZ - Monday, June 16, 2008 - link
Was AC tested with or without the patch? (the patch removes a lot of performance on the ATi cards..)DerekWilson - Monday, June 16, 2008 - link
the patch only affects performance with aa enabled.since the game only allows aa at up to 1680x1050, we tested without aa.
we also tested with the patch installed.
PrinceGaz - Monday, June 16, 2008 - link
nVidia say they're not saying exactly what GT200 can and cannot do to prevent AMD bribing game developers to use DX10.1 features GT200 does not support, but you mention that"It's useful to point out that, in spite of the fact that NVIDIA doesn't support DX10.1 and DX10 offers no caps bits, NVIDIA does enable developers to query their driver on support for a feature. This is how they can support multisample readback and any other DX10.1 feature that they chose to expose in this manner."
Now whilst it is driver dependent and additional features could be enabled (or disabled) in later drivers, it seems to me that all AMD or anyone else would have to do is go through the whole list of DX10.1 features and query the driver about each one. Voila- an accurate list of what is and isn't supported, at least with that driver.
DerekWilson - Monday, June 16, 2008 - link
the problem is that they don't expose all the features they are capable of supporting. they won't mind if AMD gets some devs on board with something that they don't currently support but that they can enable support for if they need to.what they don't want is for AMD to find out what they are incapable of supporting in any reasonable way. they don't want AMD to know what they won't be able to expose via the driver to developers.
knowing what they already expose to devs is one thing, but knowing what the hardware can actually do is not something nvidia is interested in shareing.
emboss - Monday, June 16, 2008 - link
Well, yes and no. The G80 is capable of more than what is implemented in the driver, and also some of the implemented driver features are actually not natively implemented in the hardware. I assume the GT200 is the same. They only implement the bits that are actually being used, and emulate the operations that are not natively supported. If a game comes along that needs a particular feature, and the game is high-profile enough for NV to care, NV will implement it in the driver (either in hardware if it is capable of it, or emulated if it's not).What they don't want to say is what the hardware is actually capable of. Of course, ATI can still get a reasonably good idea by looking at the pattern of performance anomalies and deducing which operations are emulated, so it's still just stupid paranoia that hurts developers.
B3an - Monday, June 16, 2008 - link
@ Derek - I'd really appreciate this if you could reply...Games are tested at 2560x1600 in these benchmarks with the 9800GX2, and some games are even playable.
Now when i do this with my GX2 at this res, a lot of the time even the menu screen is a slide show (often under 10FPS). Epecially if any AA is enabled. Some games that do this are Crysis, GRID, UT3, Mass Effect, ET:QW... with older games it does not happen, only newer stuff with higher res textures.
This never happened on my 8800GTX to the same extent. So i put it down to the GX2 not having enough memory bandwidth and enough usable VRAM for such high resolution.
So could you explain how the GX2 is getting 64FPS @ 2560x1600 with 4x AA with ET:Quake Wars? Aswell as other games at that res + AA.
DerekWilson - Monday, June 16, 2008 - link
i really haven't noticed the same issue with menu screens ... except in black and white 2 ... that one sucked and i remember complaining about it.to be fair i haven't tested this with mass effect, grid, or ut3.
as for menu screens, they tend to be less memory intensive than the game itself. i'm really not sure why it happens when it does, but it does suck.
i'll ask around and see if i can get an explaination of this problem and if i can i'll write about why and when it will happen.
thanks,
Derek
larson0699 - Monday, June 16, 2008 - link
"Massiveness" and "aggressiveness"?I know the article is aimed to hit as hard as the product it's introducing us to, but put a little English into your English.
"Mass" and "aggression".
FWIW, the GTX's numbers are unreal. I can appreciate the power-saving capabilities during lesser load, but I agree, GT200 should've been 55nm. (6pin+8pin? There's a motherboard under that SLI setup??)
jobrien2001 - Monday, June 16, 2008 - link
Seems Nvidia finally dropped the ball.-Power consumption and the price tag are really bad.
-Performance isnt as expected.
-Huge Die
Im gonna wait for a die shrink or buy an ATI. The 4870 with ddr5 seems promising from the early benchmarks... and for $350? who in their right mind wouldnt buy one.