Intel Unveils Lunar Lake Architecture: New P and E cores, Xe2-LPG Graphics, New NPU 4 Brings More AI Performance
by Gavin Bonshor on June 3, 2024 11:00 PM ESTNew NPU: Intel NPU 4, Up to 48 Peak TOPS
Perhaps Intel's main focal point, from a marketing point of view, is the latest generational change to its Neural Processing Unit or NPU.Intel has made some significant breakthroughs with its latest NPU, aptly called NPU 4. Although AMD disclosed a faster NPU during their Computex keynote, Intel claims up to 48 TOPS of peak AI performance.NPU 4, compared with the previous model, NPU 3, is a giant leap in enhancing power and efficiency in neural processing. The improvements in NPU 4 have been made possible by achieving higher frequencies, better power architectures, and a higher number of engines, thus giving it better performance and efficiency.

In NPU 4, these improvements are enhanced in vector performance architecture, with higher numbers of compute tiles and better optimality in matrix computations.This incurs a great deal of neural processing bandwidth; in other words, it is critical for applications that demand ultra-high-speed data processing and real-time inference. The architecture supports INT8 and FP16 precisions, with a maximum of 2048 MAC (multiply-accumulate) operations per cycle for INT8 and 1024 MAC operations for FP16, clearly showing a significant increase in computational efficiency.

A more in-depth look at the architecture reveals increased layering in the NPU 4. Each of the neural compute engines in this 4th version has an incredibly excellent inference pipeline embedded — comprising MAC arrays and many dedicated DSPs for different types of computing. The pipeline is built for numerous parallel operations, thus enhancing performance and efficiency. The new SHAVE DSP is optimized to four times the vector compute power it had in the previous generation, enabling more complex neural networks to be processed.

A significant improvement of NPU 4 is an increase in clock speed and introducing a new node that doubles the performance at the same power level as NPU 3. This results in peak performance quadrupling, making NPU 4 a powerhouse for demanding AI applications. The new MAC array features advanced data conversion capabilities on a chip, which allow for a datatype conversion on the fly, fused operations, and layout of the output data to make the data flow optimal with minimal latency.
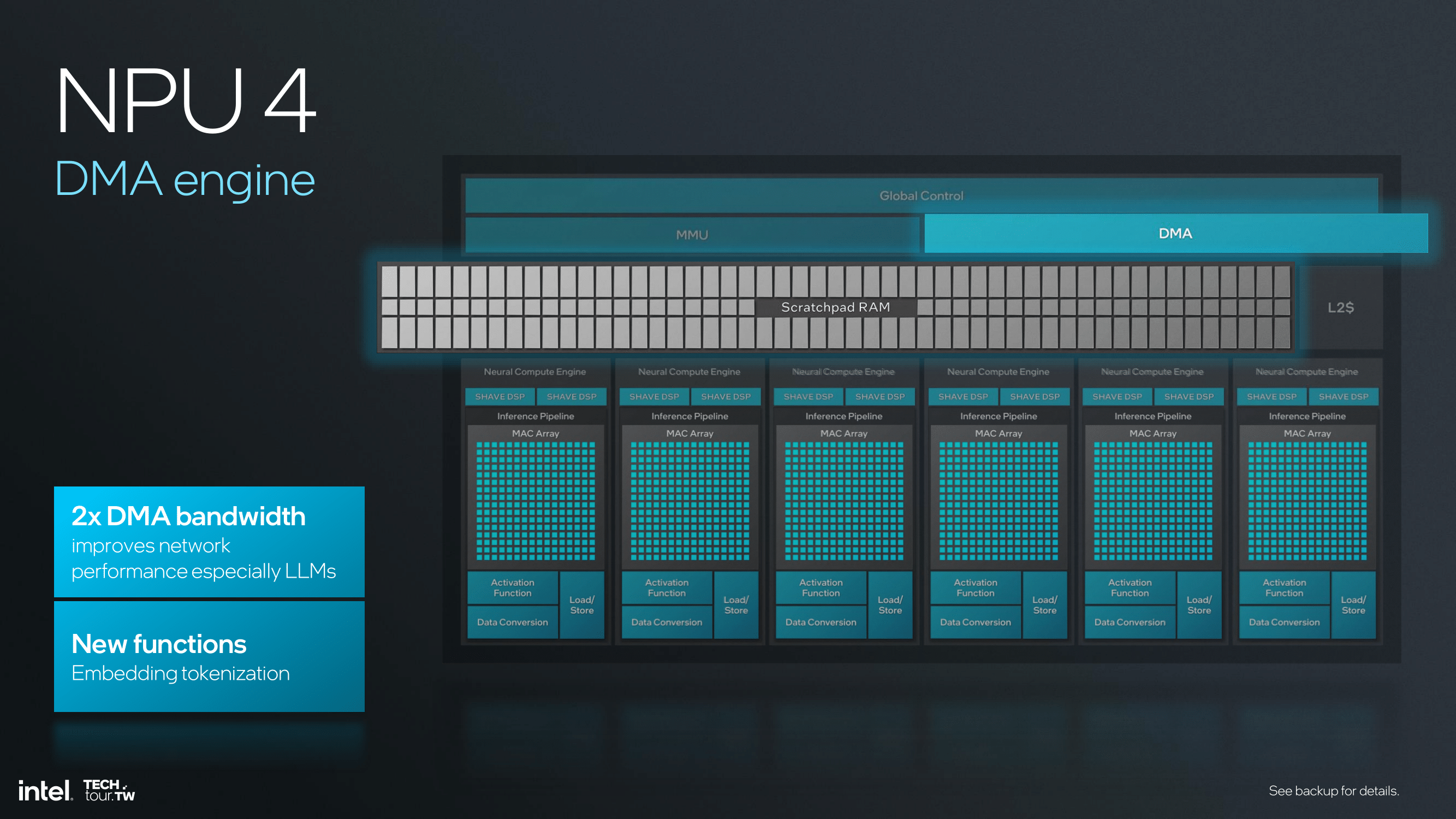
The bandwidth improvements in NPU 4 are essential to handle bigger models and data sets, especially in transformer language model-based applications. The architecture supports higher data flow, thus reducing the bottleneck and ensuring it runs smoothly even when in operation. The DMA (Direct Memory Access) engine of NPU 4 doubles the DMA bandwidth—an essential addition in improving network performance and an effective handler of heavy neural network models. More functions, including embedding tokenization, are further supported, expanding the potential of what NPU 4 can do.
The significant improvement of NPU 4 is in the matrix multiplication and convolutional operations, whereby the MAC array can process up to 2048 MAC operations in a single cycle for INT8 and 1024 for FP16. This, in turn, makes an NPU capable of processing much more complex neural network calculations at a higher speed and lower power. That makes a difference in the dimension of the vector register file; NPU 4 is 512-bit wide. This implies that in one clock cycle, more vector operations can be done; this, in turn, carries on the efficiency of the calculations.
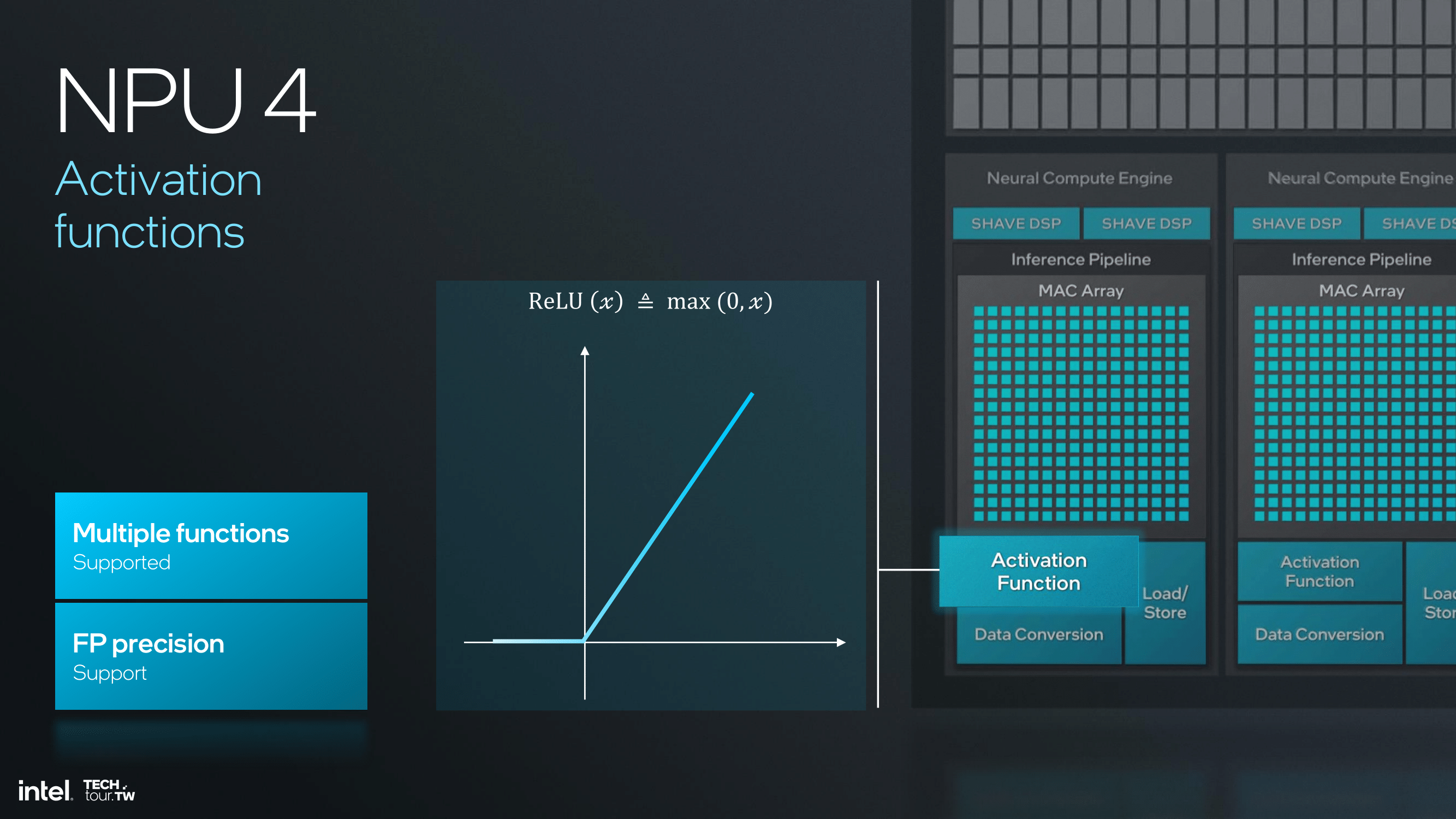
NPU 4 supports activation functions and a wider variety is available now that supports and treats any neural network, with the choice of precision to support the floating-point calculations, which should make the computations more precise and reliable. Improved activation functions and an optimized pipeline for inference will empower it to do more complicated and nuanced neuro-network models with much better speed and accuracy.
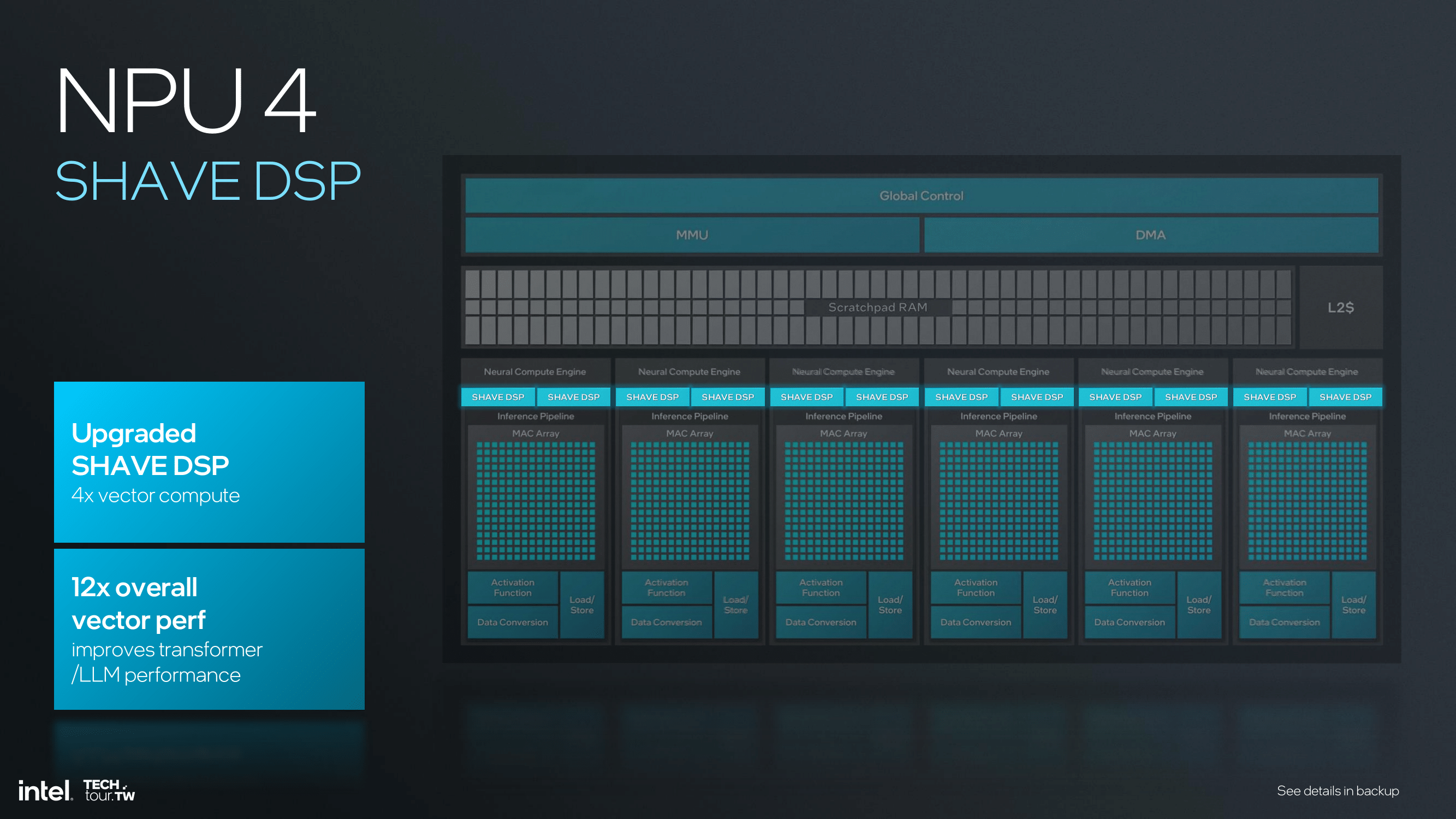
Upgrading to SHAVE DSP within NPU 4, with four times the vector compute power compared to NPU 3, will bring a 12x overall increase in vector performance. This would be most useful for transformer and large language model (LLM) performance, making it more prompt and energy efficient. Increasing vector operations per clock cycle enables the larger vector register file size, which significantly boosts the computation capabilities of NPU 4.
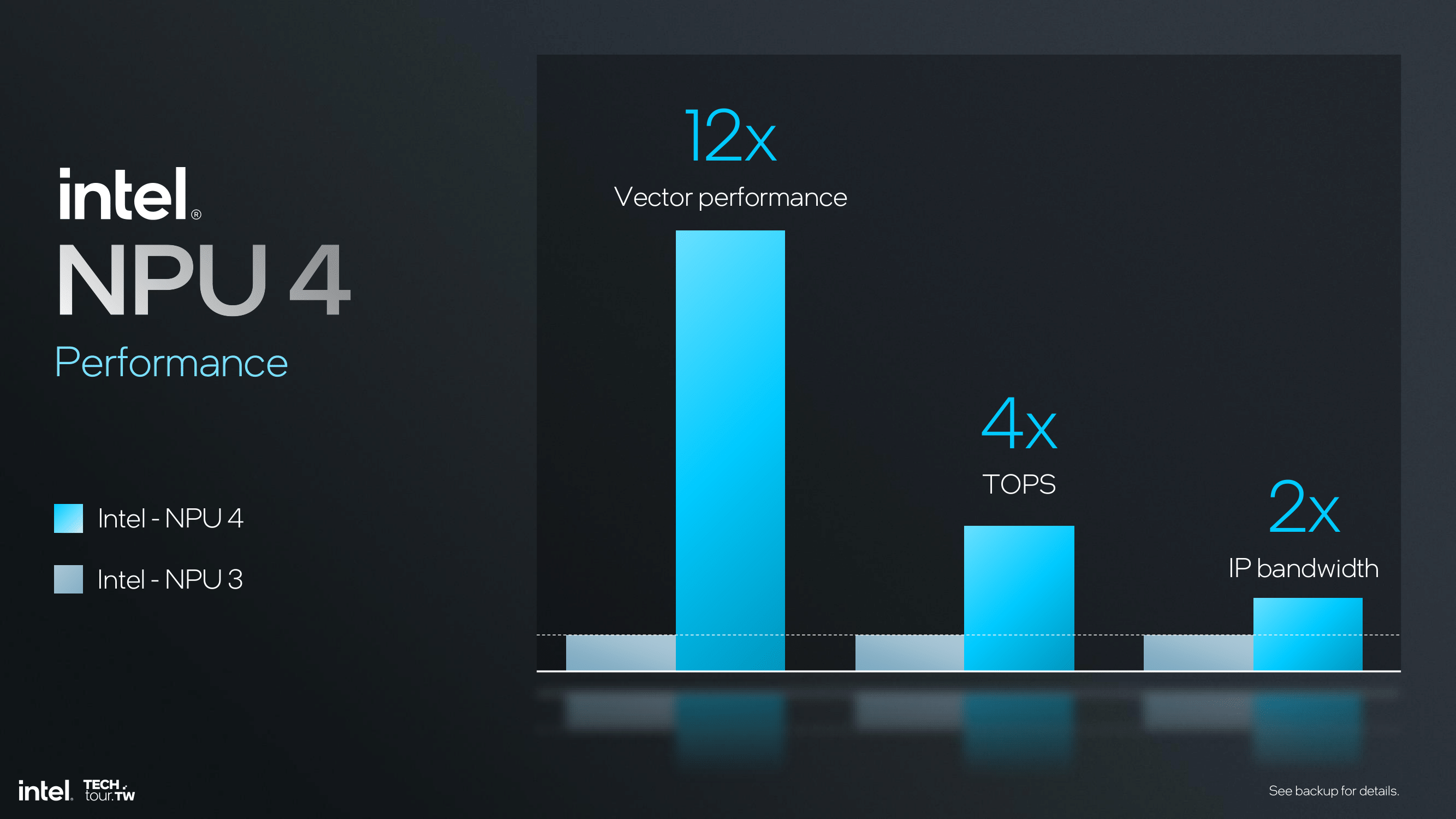
In general, NPU 4 presents a big performance jump over NPU 3, with 12 times vector performance, four times TOPS, and two times IP bandwidth. These improvements make NPU 4 a high-performing and efficient fit for up-to-date AI and machine learning applications where performance and latency are critical. These architectural improvements, along with steps in data conversion and bandwidth improvements, make NPU 4 the top-of-the-line solution for managing very demanding AI workloads.








91 Comments
View All Comments
Bruzzone - Thursday, June 6, 2024 - link
Thanks BushLin, I also find all the engineering and end use perspectives interesting as a compliment resource specific market observations I triangulate for common perspective and some not so common perspectives from time to time.My full AMD workstation, desktop and mobile what's selling in the last 6 weeks report is now posted at Seeking Alpha.
I posted here in comment string and just look down comments to the pointer and the full report is easily downloadable. There is also a pointer within the downloadable report itself to the same Intel data last eight weeks.
https://seekingalpha.com/article/4697165-computex-...
Mike Bruzzone, Camp Marketing Reply
lmcd - Wednesday, June 12, 2024 - link
if you don't understand how inventory affects pricing then stick to reddit Replyballsystemlord - Wednesday, June 5, 2024 - link
In answer to your question, "It's worth the wait to Lunar and Arrow?"In terms of Intel's CPU/GPU performance, I doubt it.
In terms of power efficiency, they might have caught up. We'll have to wait for reviews. Only partially refreshing the screen should lead to a nice performance improvement and/or efficiency improvement of the GPU.
In terms of QoL improvements, it looks like Intel went all out for this new generation. In the following statements, I'm assuming that Intel's able to deliver. Having multiple TB4 ports is useful. Having TB4 with the ability to transfer files is also useful. So is better Wi-Fi. If anything, this might be *the* killer feature of the series. Likewise, VVC, assuming it's not badly licenced, should prove useful. I wonder if VVC is supported by their Quicksync encoder...
Don't misunderstand me, I appreciate what you've said above. But I really don't see this gen failing badly unless AMD/Qualcomm can equal them in terms of useful features. Reply
Bruzzone - Thursday, June 6, 2024 - link
Ballsystemlord,I also think Intel's on it way back to mobile efficiency. While Meteor is ramping, I perceive OEMs from channel data and enterprise IT especially Intel shops on 'applications utility' value, and validation, waiting for Lunar / Arrow and or Strix. Granite Ridge I see facing an AM5 saturation issue and there is sooo much Raphael and Vermeer in the channel to clear R9K price will likely be held up while Raptor/Alder and Raphael/Vermeer nose dive on channel liquidation for capital reclaim to buy new like q4 into first half 2025.
From the channel data AMD and Intel are dumping all over Snapdragon X whose launch is into a deflationary price cycle at least through q1 2025. Lots of downward price and margin pressure.
Me, I am looking for a new (used) laptop, more a desktop replacement than Office low power and AI does not matter to me currently. I was interested in a used Tiger Octa or Cezanne H_ with MXM GPU but waiting a wee bit more because laptop prices including gaming are in a nose dive.
Means I'll be able to move up to new 13th Raptor in overage supply condition or used Alder or Rembrandt H with minimally Ampere. AMD Cezanne and Rembrandt and 13th and 12th pricing just let go and it get's better into q4. See my Seeking Alpha report on supply, trade-in and sales trend pointed to above.
mb Reply
GeoffreyA - Thursday, June 6, 2024 - link
Though my computer is all right, I'd like to upgrade to Cezanne or Renoir, either 5600G or 4600G. (It will likely be the latter because of motherboard woes.) Here, the prices have been stuck for ages. Do you think they'll ever drop? Replyballsystemlord - Thursday, June 6, 2024 - link
GeoffreyA, I'm not involved with the markets like Mr. Bruzzone, but my recent experience with trying to get a GPU for 4 years in a row says, "Yes, prices will go back down." ReplyGeoffreyA - Friday, June 7, 2024 - link
Thanks. It's just puzzling because I don't understand the markets and economic side of things too well. Replylmcd - Wednesday, June 12, 2024 - link
5600G and 4600G are weird parts because they're dependent on AMD's mobile positioning. The latter (4600G) isn't being manufactured anymore to my knowledge -- Renoir is useless now to AMD because it was supplanted in mobile by the updated Mendocino platform, which likely will never be brought to desktop. I am not sure pricing on the 4600G will ever make sense.5600G is Cezanne, which is still being manufactured for 7x30 series (or was until recently).
However, at this point Cezanne is 7nm and easily binned, but there is no direct 5600G replacement yet as AMD did not launch a 7000 series G product. The 8000G series (just announced) should push 5600G into clearance pricing. Reply
GeoffreyA - Thursday, June 13, 2024 - link
Thanks. Good explanation. I'd go for the 5600G, but my motherboard, B450 Tomahawk, apparently has issues with this very CPU, despite there being BIOS support for quite some time. Online, people haven't had a solution, and MSI says nothing. Replymode_13h - Thursday, June 6, 2024 - link
Hey, where's the rest of the slide deck? There are definitely some slides I've seen elsewhere that aren't featured in the article. I'm used to this site posting the entire slides at the end. Reply